Stochastic Answer Networks for Machine Reading Comprehension Github
Investigating the Automobile Reading Comprehension Problem with Deep Learning
Teaching machines how to do standardized exam-like reading questions.
This project and commodity was jointly done past Yonah Isle of man , Rohan Menezes and myself.

When you think about it, reading comprehension is kind of a miracle of human thinking. That we can have a piece of text and, with little to no context, gain a deep agreement of the purpose of the text and even infer facts that do not feature verbatim in the text is really quite difficult and impressive. In the world of artificial intelligence and machine learning, researchers take spent years and even decades trying to teach machines to read and embrace. Over the past few weeks, our squad has worked on solving 1 modest slice of the "reading comprehension puzzle".
How is this chore modeled?
To effectively measure how well a machine can "understand text", let'southward retrieve back to how humans are tested on their comprehension: through a standardized reading exam!
Remember these innocuous-looking, simply incredibly hard questions on exams?
Well, OK, these questions await pretty easy. But, that's non always the case! Every bit anyone who has taken a higher level standardized exam knows, reading comprehension questions tin can get quite hard. For now, we turn our focus to "fill-in-the-blank" manner questions: a machine is given a reading passage, too as a multiple choice fill-in-the-blank question, and all information technology has to do is choose the correct selection that would all-time fill the blank! Sounds unproblematic, correct?
Turns out the problem is fairly difficult for machines to learn. We phone call this "fill-in-the-bare" manner of question a cloze-manner reading comprehension task. There are many difficulties that are faced here:
- First, machines have to learn the construction and meaning of linguistic communication start. Dissimilar a man, who is already familiar with how words mesh together in a judgement and is able to "understand" the truthful pregnant behind one, a machine needs to somehow exist taught that.
- Second, it may not be obvious where to wait in a passage for the answer to a question. One could spend a really long time looking for an answer in a piece of text and it could be right there staring at them on the page! For machines information technology's even harder; since language is highly flexible a sequence of words that you are looking for might non show upward word-for-give-and-take in the passage.
With reading comprehension being so difficult, there's no singular approach machines can accept to solve the problem. So, now what do we exercise?
Permit's add a little…Car LEARNING!
Why don't nosotros use the power of auto learning to help usa solve this problem?
Motorcar learning has emerged to exist an extremely powerful technique in reading text and extracting important concepts from it; it's been the obsession of most computational linguists for the past few years.
Then allow's brand this obsession a good 1 and put information technology to employ in our problem!
First, a brief detour: nosotros're going to be using the CNN/Daily Mail dataset in this projection. Take a look at an example document/query:
( @entity1 ) information technology's the kind of matter you meet in movies, like @entity6's role in "@entity7" or @entity9'south "@entity8." but, in real life, it'southward hard to swallow the idea of a single person being stranded at sea for days, weeks, if not months and somehow living to talk near it. miracles exercise happen, though, and not merely in @entity17…
Query: an @entity156 man says he drifted from @entity103 to @placeholder over a year @entity113
Each document and query has undergone entity recognition and tokenization already. The goal is to judge which entity should be substituted into "@placeholder" in order for the query to make sense.
Our goal now is to formulate this as an appropriate machine learning trouble that nosotros can train a model and use it to predict words correctly. In spirit of this, we can actually form our problem every bit a binary nomenclature trouble; that is, given a new certificate and query pair, we can transform it into a set up of new "certificate-query" pairs such that a certain subset of them correspond to correctly guessing an entity fits the blank, and the other subset corresponding to negative examples, i.e. correctly guessing that an entity should not fill the blank.
For every document-query pair, nosotros as well create some features to associate with the pair, since feeding the unabridged pair into a auto learning model at this point is infeasible.
We utilise a logistic regression model to implement this problem. Subsequently grooming the model, we achieve an accuracy of 29%, pregnant that 29% of the documents had the bare filled in correctly. For context, most documents in the dataset incorporate virtually 25 entities, so randomly guessing a discussion for each document would have an accuracy of roughly four%. And then this model performs pretty decently!
The logistic regression model performs okay, but if we're beingness honest, 29% accuracy isn't exactly "homo-like". And so, how can nosotros make our model acquire more effectively?
Hither is where deep learning comes into play. When humans read text, they don't just learn a few heuristics about the text and then make guesses based off of those heuristics. Rather, they learn to empathize the underlying pregnant of the text and to make meaningful inferences based off of their understanding. That is our goal with this problem besides! Deep learning will provide us with the tools we need to truly teach machines to read.
WIth a new approach comes new goals. From now we on, we don't desire to limit this trouble to that of a binary classification problem, rather we view this problem more holistically — our model will be allowed to cull any give-and-take in the document equally the correct entity to "fill in the blank". This is more representative of bodily learning then our previous formulation.
Behold…deep learning
Using these motorcar learning techniques is great and all, but can nosotros practice ameliorate than this? On the 1 paw, logistic regression is an effective machine learning model to use and is a quick style to get a baseline accuracy, but it falls short on several aspects. The manner that logistic regression decides whether a word should make full in a blank is as well rigid; namely, logistic regression can only larn linear functions, which aren't that suitable for a broad range of issues.
This is where we tin can now turn to deep learning and the power of neural networks for our problem. Neural networks are a contempo hot development in machine learning that allow us to acquire more complex functions than normal models like logistic regression tin can.
In this article, we'll consider a special kind of neural network, chosen Long Short-Term Memory, or LSTM for curt. Here'due south what the LSTM looks like:
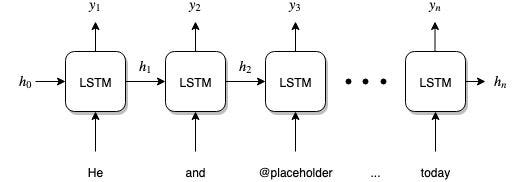
Seems complicated, just if nosotros pause it downwardly piece by piece, we tin sympathize what this network is doing. Imagine reading over a sentence: give-and-take by word, your mind is thinking about the sentence every bit you lot read and is formulating thoughts petty by petty. The aforementioned goes for an LSTM; it will have in each give-and-take of a sentence and generate a hidden country subsequently seeing a word. You can think of this subconscious state every bit the thought that the LSTM transmits to the next time pace when it comes fourth dimension to read the next give-and-take.
In the context of our problem, we tin can feed the passage followed by the question into our LSTM, and finally guess which word would best fit the blank in the query based on the concluding output of the LSTM. (If you're wondering how to obtain the final word, the style we obtain this is past taking our output from our LSTM, and creating a list of probabilities for every possible word that can possibly make full the bare discussion. We so choose the word that has the highest probability.)
What is special nearly the LSTM (versus other networks that have a like structure) is that an LSTM is able to "think" information nigh words over long ranges in the judgement, and exist able to "forget" information apace when necessary. This allows an LSTM to decide what is of import in looking at a certain word and what it needs to retrieve for previous words.
You lot may now ask: "how do we feed words into a network?" We could feed in the actual strings into the network, but it's hard for neural networks to parse raw strings of data. Instead, we represent each word using embeddings. This involves representing each word using a stock-still-length vector, then that information technology is easy for the LSTM to run computations on the words. Ideally, nosotros want words that accept to practise with each other to exist "closer" to each other with respect to their embeddings.
Fortunately, the great minds at Stanford NLP have already done this chore for us; they have a downloadable set of embeddings called GloVe (Global Vectors for Word Representation) that have proved to exist very effective in natural language processing tasks. We use these in our models, and achieve a stunning increase in accuracy: 39%! This comeback over the base not-deep model signifies the power of deep learning in beingness able to model this job, as well as the power of the LSTM.
The linear regression and BiLSTM loss curves. Note how the BiLSTM loss rate drops, this is a sign of fantastic learning!
Can we do better?
Simply at present we over again inquire: tin we do better? The answer to this is likewise a stiff yes! At a high level, what nosotros desire to do is make our model think more like a man does. As humans, when nosotros perform a reading comprehension job, nosotros don't just read the text and and then guess what should go in the bare; rather, we like to look at the query for clues as to which words in the document are more relevant and should be considered more closely. Similarly, for our model we introduce the concept of attention. The goal of attention is to generate a matrix whose values represent the relative "attention" the model should requite to each document give-and-take.
Why Attention?
The intuition for attending comes from the way humans think. For example, when nosotros perform a reading comprehension chore, we use the query to guide our reading of the text. Nosotros focus in on detail portions of the text that are more relevant for the query and ignore portions of the text that are irrelevant. We want to do the aforementioned thing with our model. We would like the machine to understand which portions of the text are relevant to the query and focus in on those portions. The architecture described below attempts to practice merely that.
Our Compages:
In that location are many means to implement attention, only we chose a variant of the "Sum Attention" model described above. Every bit with in the above diagram, nosotros brainstorm feeding our certificate and query into carve up GRU modules (GRUs are LSTMs with a few more than bells and whistles). The output of each GRU is then processed as follows (this is the attention part of the model!). Nosotros start calculate what is known every bit "query to document attention". What this ways is that the model tries to understand which of the certificate words are the almost important given one word of the query. Merely this returns a different value for each of the of the query words, so the question becomes: if each query discussion places dissimilar importance on unlike document words, how do nosotros decide which query words nosotros should actually heed to?
To do this, our model now asks the question: given a particular document word, how important are each of these query words? This gives united states a measure of the importance of each query word. We then average the importance of each query word to get a final importance. This last importance is then combined with the previously calculated importance of different document words to calculate a final weighted average of attention for each certificate word.
Finally, nosotros implemented our own innovation to endeavour to better this model farther. This model assumes that if a document word and a query word place high importance on each other, their representation will be very similar. Nevertheless, we attempt to improve on this by trying to let the model learn the importance relationship between the certificate and the query. Similar to how we as humans effigy out how much weight to identify in our agreement of a text and how much weight to place in the connection of the text to the query, we as well want to let the car to learn this relationship. Our hope is that this gives the machine a more nuanced view of the text and the question being asked.
At the time of writing we take not yet managed to get good results for our current architecture. We don't believe that this is due to a flaw in our model, but rather a result of the difficulties in training complex deep learning models in general. Amongst the about important lessons we take from this project is that building these models is extremely difficult and testing and bug-fixing can be very time-consuming. We hope to exist able to refine this model more in the future and accomplish a better accuracy every bit the base model.
Lastly, the most important lesson nosotros have taken from this project is the effectiveness of deep learning to teach machines to solve complex problems. The original attention over attending model that nosotros modeled our architecture off of had a final test accuracy of over 70%. That's a massive improvement over the non-deep baseline of 29%! Deep learning shines in bug similar this and we're hoping to continue and bolster future work on this task to accelerate the field of car comprehension further.
For a link to our newspaper that goes over more of the technical details, meet this link .
Many thanks go out to Jeffrey Cheng , David Rolnick , and Konrad Kording for their Jump 2019 offering of CIS 700 (Deep Learning) at the Academy of Pennsylvania, and their abiding educational activity and mentorship throughout this project.
Source: https://towardsdatascience.com/investigating-the-machine-reading-comprehension-problem-with-deep-learning-af850dbec4c0
0 Response to "Stochastic Answer Networks for Machine Reading Comprehension Github"
Post a Comment